Arduino / Electronics / Lab / Tutorials
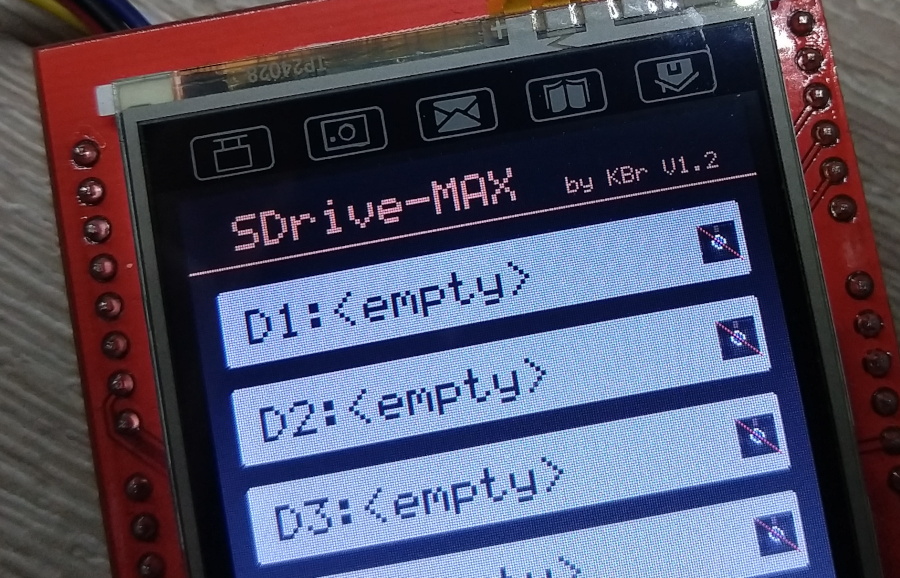
RFID / PIN Lock with a STONE Display
 by
by So in my first adventure with the STONE displays I wrote a simple Arduino library to communicate with them, and ported the firmware-side of the …
A maker / gamedev's blog or something.
Tutorials, advice, snippets of code, sketches, etc. Everything that actually teaches something with examples or code will hopefully end up in this category.
So in my first adventure with the STONE displays I wrote a simple Arduino library to communicate with them, and ported the firmware-side of the …
HMI?! HMI stands for Human Machine Interface, which is a fancy way of describing an element that enables the interaction between a human and a …
One of the things I’ve been interested in for the last year or so, is developing for the Atari family of 8-bit computers. I haven’t …
You don’t see them around that much anymore, but a few years ago the ESP-01 modules took the world by storm as quick “serial to …
I got the chance to play with an Intel Edison board a couple of months ago, and I just got my own board today, so I spent a …
Not long ago I purchased this neat and compact DC to DC Buck Boost converter that performs reasonably well. It has a maximum output of 38V, …
For a few months now (and after successfully using a cheap USB analyzer with my Pocket C.H.I.P) I’ve wanted to make a sort of standalone Logic Analyzer / …
A recent discussion on the Pocket C.H.I.P forums made me dig up memories of my time with DJGPP (a wonderful DOS port of GCC), and …