Arduino / Atari / Development / Tutorials
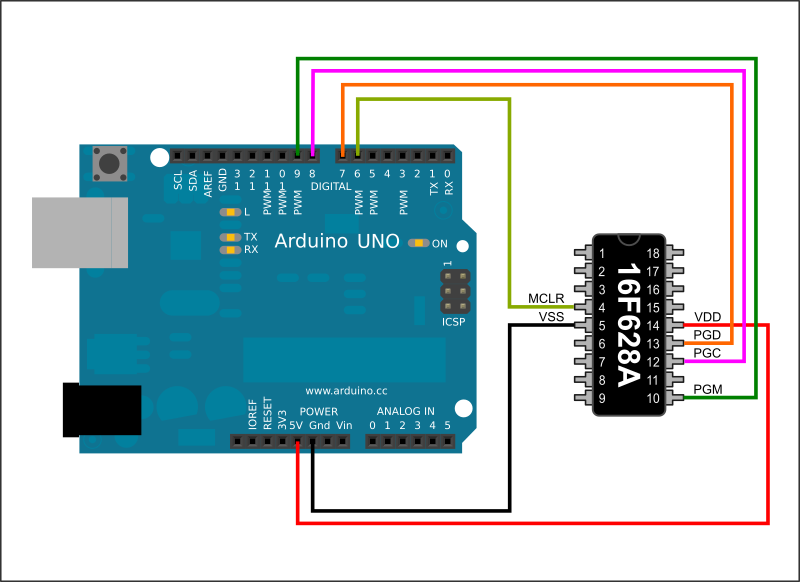
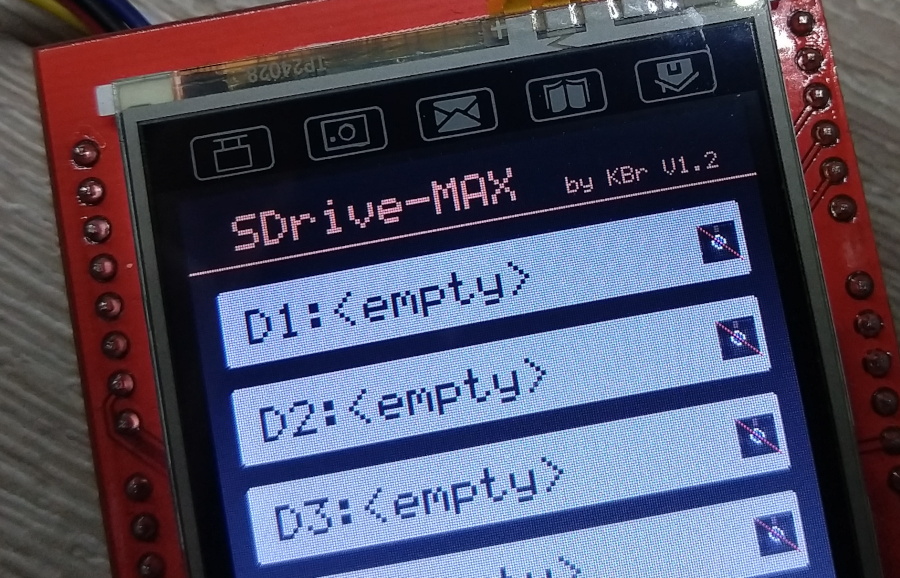
SDrive-Max Using a cheap 2.4 TFT LCD
 by
by One of the things I’ve been interested in for the last year or so, is developing for the Atari family of 8-bit computers. I haven’t …
A maker / gamedev's blog or something.
One of the things I’ve been interested in for the last year or so, is developing for the Atari family of 8-bit computers. I haven’t …
A couple of months ago I was asked if I could prepare a sort of workshop on one of my favorite topics: ASM Programming for …
It took me a really long time to do this second part of my Pi-based Logic Analyzer project, mostly because of two things; the first one …
I got the chance to play with an Intel Edison board a couple of months ago, and I just got my own board today, so I spent a …
If you are using your Arduino’s PRNG (Pseudo-Random Number Generator) for anything more serious than flashing random lights for your Christmas decorations, there’s a chance you might run …
For a few months now (and after successfully using a cheap USB analyzer with my Pocket C.H.I.P) I’ve wanted to make a sort of standalone Logic Analyzer / …
A recent discussion on the Pocket C.H.I.P forums made me dig up memories of my time with DJGPP (a wonderful DOS port of GCC), and …
So a time ago I purchased a cheap USB Logic Analyzer from eBay that works great with a PC, and it’s been really helpful to debug several …