 by
by DISCLAIMER: Over the course of this post I’ll be dealing with parsing, programming practices, code refactoring, SPI bus oddities, caching techniques,etc. It’s a mixed bag of things and it’s far from being serious analysis on the topic of optimization. Please don’t expect anything particularly smart in this post like branch prediction, overlapping cache windows, partial block reads, etc. This is just a chronicle of sorts, of the things I’ve done over the past few hours to improve the performance of my Brainfuck-on-Arduino interpreter, which was being painfully slow.
So in my previous post you hopefully got a glimpse of my current project: a Brainfuck interpreter running completely on Arduino. Something that I forgot to mention is that all the input/output (for testing purposes) currently happens through a serial connection. I’m using the “Serial Monitor” console that’s part of the Arduino IDE to “talk” with the board and run the code.
I’d also like to point out that I’m using an external 23K256 chip for the Brainfuck data space, This is basically a 32KB RAM IC that is accessed via SPI (Serial Peripheral Interface). This is relevant for some of the optimizations I’ll do next.
The test I’ll perform after each “optimization” is to run a brainfuck function that generates the first <100 numbers in the Fibonacci sequence.
For comparison here’s an image from my previous post where you can see that it actually takes almost 11 seconds to run that program when executed directly from a FAT16-formatted SD Card:
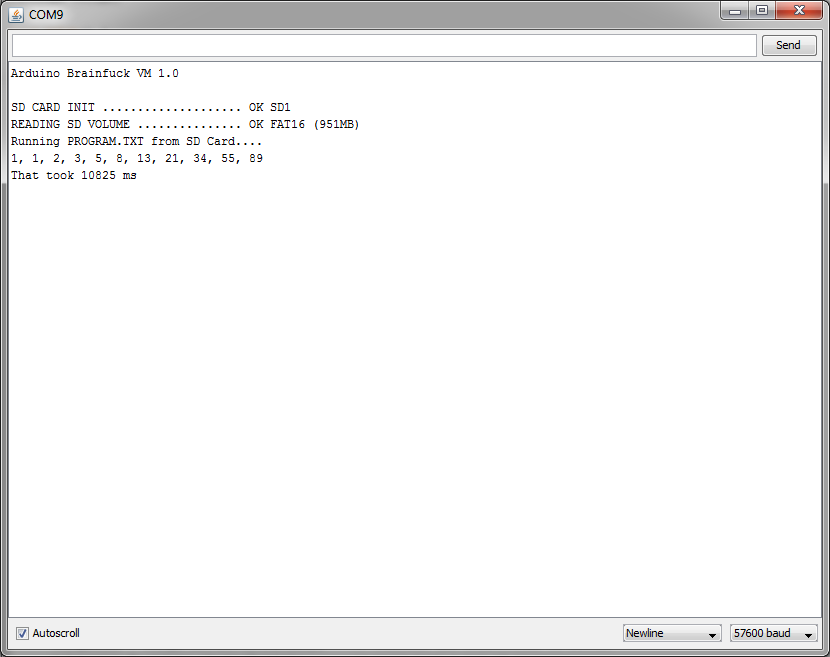
That’s BAD. REALLY bad.
It performs better (but still unbearably slow) when we read the code from RAM, so that’s what we are going to use for the purpose of this experiment. There won’t be fancy screenshots now because it’s kinda pointless to repeatedly screen-cap a console that only shows text.
The same code, executed from RAM and using the still-unoptimized interpreter takes around 3.7 seconds to run. This is our starting point:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 3676 ms
Application-related problems
A key point in brainfuck programs are “loops”. My current implementation deals with loops by means of a stack where I keep track of the “entry points”. When we enter a loop, I push the current program address to the stack. When we find the “end of loop” instruction and we need to go back to the point where the loop started, I know exactly where to go by just looking at the top of the stack. Once we exit a loop this address is popped-out from the stack. This of course works perfectly with nested loops.
I know what you are thinking: I can’t really have a stack that grows forever in a platform with barely 2KB of RAM, sure, and because of this my current implementation has a limit on the “depth” of nested loops. As I can easily store around 200 loop points in the available memory it’s safe to say it’s not really a limitation, though. I’m yet to see code with loops nested more than 5 or 6 levels down.
Now I can obviously do this in a different way: I can ditch the stack and deal with “end of loop” instructions by scanning the code in reverse until I reach the point where the loop started.
To do this we go over the program code from the current position back to the start of the program, keeping a counter that is increased by every “loop end” instruction we find, and decreased by every “loop start” in the way. The process stops when the counter reaches zero and we find a “loop start”. This takes no RAM (except for the counter) and I kinda expected this to be slower than my stack-based solution…
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 2718 ms
But I was wrong. That’s a whole second faster than with a stack!!
Who would have thought that going over the code instruction by instruction every damn loop is apparently faster than looking up a number in memory and performing an insta-jump?. This got me scratching my head until I remembered that I had my stack of loop-points stored in the external SPI RAM (because the SD functions were using too much RAM from my device).
This means that every read and write from this Stack requires communicating with the SPI RAM IC, something that happens at 1/4 of the processor speed and ALSO is performed by sending and receiving bytes of data bit per bit (which means that it takes a lot of instructions to read or write a single bit from memory). Addresses are also 4-byte wide (DWORD) so each access requires 32 bits to be transferred over SPI.
As I’m no longer making tests with Arduino’s SD Card library I can move the stack back to the internal RAM of the AVR controller and try again:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 2596 ms
Ok, that’s better and actually makes sense. The stack solution is faster than scanning the code when the stack resides in the AVR internal RAM. The difference is barely 200 ms for this program, but I expect it to be larger with more loop-intensive code.
Although we’ve managed to improve performance by moving the loop-point stack back to the internal RAM, there’s a lot that can still be done by checking the critical parts, which are the ones that get called more frequently.
Code oddities and Caching
My code relies a lot on my own SPI routines, which are (were) inside a “HW_SPI” class I made. Since it only had 4 methods (init, read, write and setClock) I decided to take them out of the class and implement them as global functions, to see how that affected performance. They are called for every RAM access so the more straightforward to invoke they are, the better. Surprisingly this reduced the execution time by a lot:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 2291 ms
Now, BF code is being parsed by a simple switch() block inside a while loop. Since there are only 8 instructions and they don’t take arguments, this is probably the most natural approach.
Replacing the switch by a set of if…else if…. actually reduced the execution time by around 80 ms. Moving the “most frequent” instructions (pointer and math operations) to the top of the if/else ladder helped a lot. The loops are rather unusual statistically inside BF code, so moving them down the sequence of conditional tests makes a lot of sense.
The next step was optimizing RAM access. Whenever I find “increment” or “decrement” instructions, my code reads the current cell from the SPI RAM memory (slow, as it has been shown before), then increases or decreased the value obtained accordingly, and then writes it back (slow as well).
This is inefficient, so I wrote a small “wrapper” class that keeps track of the current memory cell. Once we read the current cell from the SPI RAM we keep its value in memory and we avoid reading it again (until we move the cursor to another cell). Every successive read operation performed without moving the RAM pointer will be extremely fast, as we already know what the value of the current cell is, without having to bother “talking” to the RAM IC again. When a “write” operation is requested, we just update the value we have in memory. We do NOT write the value back to the SPI RAM until the memory cursor is moved to another cell (this is called a write-back policy). This is basically a 1-byte cache, and it improves the performance noticeably:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 1761 ms
Now I took the idea further. Instead of keeping a single byte in memory I decided to keep a whole block of 256 values. When a read is requested, a whole “page” of 256 bytes is read, and we operate with this cached copy until we cross the page boundaries and request either a read or write operation. Just THEN we dump the previous “page” to the SPI RAM chip and read the new page. We are relying on the concept of locality here: most code will most-likely operate over a narrow number of cells, reading and writing values from close locations. I doubt that someone will deliberately alternate between two very distant cells. This is a similar strategy to the one used by modern processors with their CPU caches (L1, L2, etc).
Of course this means that this code won’t perform very good if we happen to alternate a lot between cells that are in the limit of two “pages” (oscillating between cell number 255 and 256 for instance will cause successive page refreshes. We will reload a whole page for each access to them). Now this is a rather unlikely case that we should NOT find often, and since I don’t intent to write code directly in brainfuck but through a compiler, this can also be completely avoided by generating code that is careful around “page borders”.
With the 256-byte cache, this is what I get:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 771 ms
At this point I am really pleased with the results. We shaved off like 3 seconds from the run-time. Computing Fibonacci numbers now takes like 20% of what it used to.
Please note that the Fibonacci function is probably not a good test for a 256-bytes cache as it probably doesn’t even cross the page boundary once, but it’s clear how decreasing the number of read/write operations to the SPI RAM drastically reduces the execution time. I fiddled a bit with RAM “paging” code to purposefully trigger page swaps and when using 32 byte pages the code takes around 940 ms. There are obviously some page switching going on there, but it’s still a significant improvement over the single-byte “cache”.
I’ll stick with the 256-byte pages though. The larger the RAM “page”, the fewer read/writes operations that will be performed in most cases.
But I noticed there was another improvement that could be done. The SPI-RAM can work in different “modes” and I was using two of them (“sequential mode” for reading/writing large blocks, and “byte mode” for reading/writing single bytes).
As I no longer had a need to quickly alternate between the modes (as I will mostly stay in sequential mode for reading whole “pages”) I wrote code that keeps track of the current access mode and only performs a mode switch when the mode needed for the operation differs from the one we used last. This small improvement takes the time down to this:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 752 ms
We can further improve the numbers by cheating a bit. we can move the RAM blanking (normally performed before executing the code) outside the parsing routine and do it only when the platform starts. This takes the time down to this:
-- RUNNING CODE -- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 That took 642 ms
Now this is a number I’m happy with.
I expect the performance to drop considerably if I read the program code from a SD Card instead of RAM, BUT I plan to implement a cache system similar to the one I implemented for the RAM. Program memory doesn’t change in run-time so I only have to read blocks, which is a rather fast operation. Bringing a whole sector of 512 bytes into memory takes around 2 ms, so the performance hit should be minimal.
I’d also like to note that I’m currently using the SPI bus at 4 Mhz, which is the fastest speed I could make it run despite every device on the bus supporting >16 Mhz frequencies. The highest frequency at which this processor can operate the SPI bus is 8 Mhz I think, but I only get garbage from both the SD Card and the SPI memory if I set the SPI clock that high.
It could be that the 4050 level shifter I’m using it’s too slow to reliably downstep the 5V signals from the Arduino board to 3.3V at 8Mhz, so I’ll try using a different approach for the level conversion and see if I can double the bus speed. That should mean another significant increase in performance. We shall see.
UPDATE: I managed to boost the SPI bus frequency to 8Mhz by tying the unused input pins of the 4050 to ground (which is a good practice according to the datasheet) and while it was reliable enough for the SPI RAM to happily work at that speed, it wasn’t good enough for the SD card. Perhaps the signals were too noisy at 8Mhz (totally possible considering I’m still testing on a breadboard) or too unstable, I don’t really know. However, this didn’t really make a difference in the performance, and I’ll explain why in my next post.






